Embedded Development Board Learning
RTOS Introduction for Embedded Systems
Date: septiembre 5, 2024
Author: Guillermo Garcia
Categories: RTOS Tags: FreeRTOS

In the first article of the FreeRTOS series, we will start with a general introduction to real-time operating systems. For embedded systems, this article is applicable to any RTOS kernel.
Table of Contents
Defining an RTOS
You probably know what an operating system is, as we use them all the time on everyday computers; we refer to OS software like Windows, Linux, among others. The concept is quite similar for embedded systems: a microcontroller represents the hardware, and it requires software to manage the resources through a code fragment that plans how the system resources are used.
However, it is important to understand the difference between a traditional OS and an RTOS for embedded systems.
| SO | RTOS |
| Its purpose is to manage resources aiming to achieve the highest performance for the user’s convenience. SO: Windows Linux Android macOS | Its purpose is to make the system deterministic, ensuring that its response time to events is almost constant. RTOS: FreeRTOS QNX VxWorks Zephyr |
Let’s define a concept that is crucial when an embedded system uses an RTOS.
What is a Real-time system?
Any system that has a deterministic response to a given event can be considered Real-time. In a deterministic system, randomness does not intervene; that is, the system will always produce the same result from a given starting condition. With this, we can say that if an embedded system does not meet a timing requirement when reacting to an event, it is not a Real-time system.
How can we ensure that a system can consistently react within a specified time frame to an event? This is achieved with a Real-time Operating System (RTOS) that ensures multiple processes can respond to an event.
RTOS kernels components
Although many Real-time Operating Systems (RTOS) can be scaled up or down to meet application requirements, most RTOS kernels contain the following components:
- Scheduler
- Objects
- Services
We will examine each part of a common RTOS kernel in detail.
Scheduler
The scheduler is one of the most important components of any RTOS. It encapsulates a set of algorithms that allow for the customization of task execution in an application.
Introduction to multitasking
Multitasking is the ability of the operating system to manage multiple activities within established time frames.
The traditional way a common program is executed involves using a super-loop, where function calls are repeated cyclically.
int main()
{
while(1)
{
func1();
func2();
func3();
}
return 0;
}
When working with simple programs, this approach is usually sufficient, but as we have more events to handle, things start to get complicated. If you don’t believe it, let’s look at a specific case: if func1(); takes 10 µs to execute once through the cycle, and then 100 ms the next time around, func2(); will not be called as quickly the second time through the cycle as it was the first time.
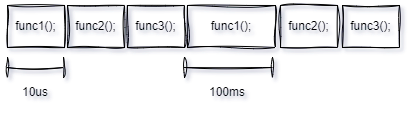
This creates a delay between the moment an event occurs and the moment func2(); detects it. In critical application systems, these time changes are referred to as latency and are often highly demanding; they must be minimized depending on the application.
It is true that this can be addressed without directly using an RTOS. There are different ways to solve these issues, such as combining the super-loop approach with interrupts.
Difference between RTOS and Super-Loop
Let’s discuss the main differences between a super-loop and an RTOS. This will help us introduce the concept that most differentiates programming with an RTOS: tasks.
Tasks, processes, or threads are code fragments that execute independently and have a private stack context:
- Each task receives its own private stack, unlike a super-loop in the main function, which shares the system stack. Tasks have their own stack that no other task in the system can use.
- Each task is assigned a priority. This priority allows the scheduler to make decisions about which task should be executed.
- The time it takes to execute each task is irrelevant in an RTOS because the loop of each task can be considered isolated from the other tasks in the system.
If we structure this in code, the super-loop looks like this:
void func1(void)
{
//! Code here event
}
void func2(void)
{
//! Code here event
}
void func3(void)
{
//! Code here event
}
int main()
{
while(1)
{
func1();
func2();
func3();
}
return 0;
}
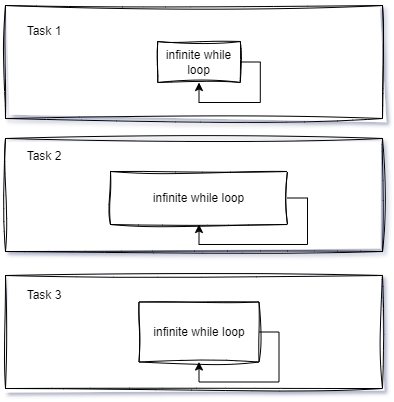
Let’s see the change when each function now represents a task, and the order for executing these tasks, that is, the execution times, are handled by the scheduler of our RTOS.
void Task1(void)
{
while(1)
{
//! Code here event
}
}
void Task2(void)
{
while(1)
{
//! Code here event
}
}
void Task3(void)
{
while(1)
{
//! Code here event
}
}
int main()
{
CreateTask(&Task1);
CreateTask(&Task2);
CreateTask(&Task3);
SchedulerStart(); //! Never returns
return 0;
}
The time a task spends using the CPU within its infinite loop is no longer a problem, as the programmer will allocate appropriate CPU time for each task. This is where multitasking comes into play: the kernel will create an environment where all tasks can execute simultaneously.
How is this possible? How does the scheduler manage to run all tasks in parallel if we only have one CPU? This is a good question. In reality, they are not running in parallel; this effect occurs thanks to context switching, which the scheduler performs periodically.
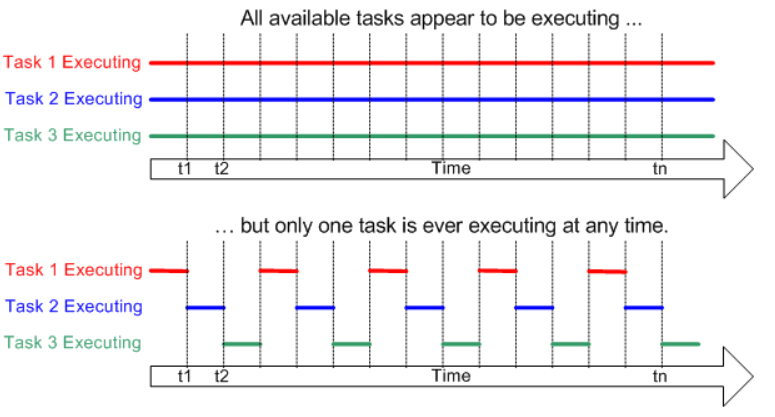
The Context Switch
Each task has its own context, which is the state of the CPU registers necessary every time its execution is scheduled. A context switch occurs when the scheduler switches from one task to another.
Every time a new task is created, the kernel also creates and maintains a Task Control Block (TCB) associated with it. TCBs are system data structures that the kernel uses to keep task-specific information.
When the kernel scheduler determines that it needs to stop executing Task 1 and start executing Task 2, it performs the following steps:
- The kernel saves the context information of Task 1 in its TCB.
- It loads the context information of Task 2 from its TCB, making it the current execution thread.
- The context of Task 1 is suspended while Task 2 executes. However, if the scheduler needs to execute Task 1 again, Task 1 resumes from where it left off just before the context switch.
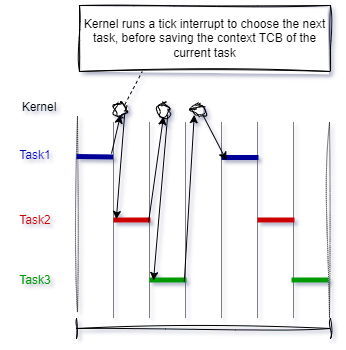
Now imagine that a tick interrupt is configured with a short period, such as every 1 millisecond. This causes the scheduler to perform a context switch every 1 millisecond, so each task receives CPU time periodically. Due to the high rate of tick interrupts, it appears as though tasks are running in parallel on a single CPU.
The Dispatcher
The dispatcher is the part of the scheduler that performs context switching and changes the flow of execution. At any time when an RTOS is running, the flow of execution, also known as control flow, is in one of three areas: through an application task, through an ISR (Interrupt Service Routine), or through the kernel.
When it’s time to exit the kernel, the dispatcher is responsible for transferring control to one of the user application tasks. It will not necessarily be the same task that made the system call. The scheduling algorithms determine which task will run next. It is the dispatcher that does the actual work of context switching and transferring execution control.
Let’s discuss the algorithms that determine which task will run, as they are a fundamental part to consider in any RTOS.
Scheduling Algorithms
As we have seen so far, the scheduler determines the switch from one task to another at each interrupt tick. But how does it do this, and in what order? Well, it clearly follows a series of steps known as the scheduling policy.
Scheduling policies can vary between different RTOSs, but the basic algorithms are:
- Co-operative scheduling
- Round-robin scheduling
- Preemptive scheduling
Co-operative scheduling
Cooperative scheduling, also known as non-preemptive scheduling, is perhaps the simplest algorithm where tasks voluntarily relinquish the use of the CPU when they have nothing useful to do or when they are waiting for some resources to become available.
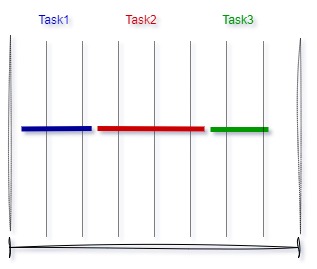
This algorithm has the main disadvantage that certain tasks can consume excessive CPU time, preventing other important tasks from executing when needed. Cooperative scheduling is only used in simple multitasking systems where there are no time-critical tasks.
Tasks execute one after another within the main infinite loop formed by a while statement. In this simple approach, tasks can communicate with each other using global variables declared at the beginning of the program.
Round-robin scheduling
Round-robin scheduling assigns each task an equal share of CPU time. Tasks are placed in a circular queue, and when the assigned CPU time for a task expires, the task is removed and placed at the end of the queue. This type of scheduling may not be satisfactory in any real-time application where each task can have a variable amount of CPU requirements depending on the complexity of the processing involved.
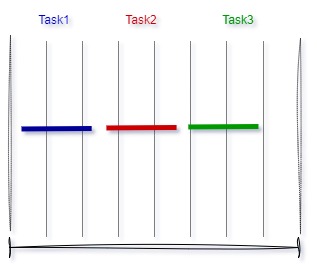
Round-robin scheduling requires that the context of the running task be saved in the stack when a task is removed from the queue so that the task can resume from the point where it was interrupted when it is reactivated.
Preemptive scheduling
Preemptive scheduling is the most commonly used scheduling algorithm in real-time systems. In this case, tasks are prioritized, and the task with the highest priority among all other tasks gets the CPU time. If a task with a higher priority than the currently running task is ready to execute, the kernel saves the context of the current task and switches to the higher-priority task by loading its context.
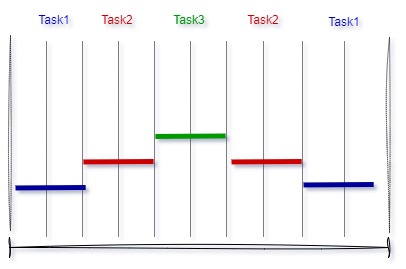
Generally, the highest-priority task runs until it is completed or becomes blocked, for example, waiting for a resource to become available or calling a function to delay its execution. At this point, the scheduler determines the highest-priority task that can be executed, loads its context, and begins executing it.
Objects
Kernel objects are special structures that constitute the basic components for developing applications for real-time embedded systems. RTOS kernel objects provide tools for managing application resources. These components are common in any RTOS.
- Very flexible task priority assignment
- Queues
- Binary semaphores
- Counting semaphores
- Recursive semaphores
- Mutexes
- Tick hook functions
- Idle hook functions
- Stack overflow checking
We will see how these objects work and when to use them in an application throughout this series, so for now, let’s stay calm.
Services
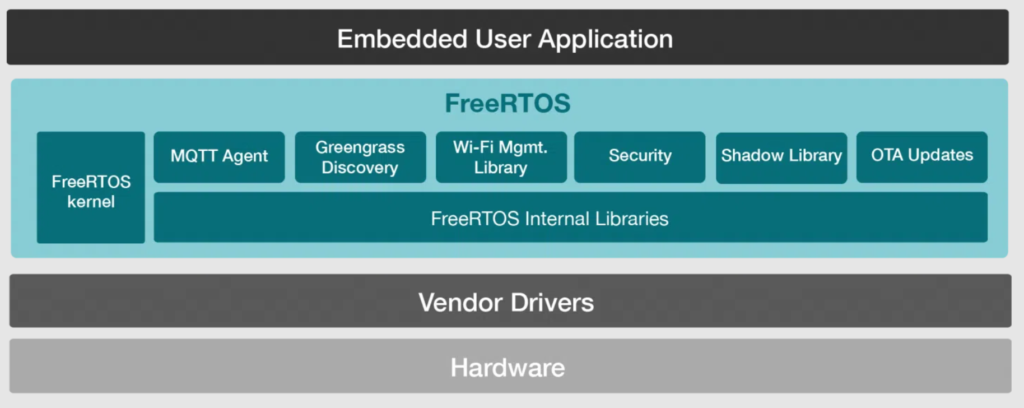
Along with objects, most kernels provide services that help developers create applications for real-time embedded systems. These services include sets of API calls that can be used to perform operations on kernel objects or can be used generally to facilitate timer management, interrupt handling, device I/O, and memory management.
Additionally, there are stacks for network connectivity, such as TCP, MQTT, and sockets for cloud connectivity.
Hard and Soft Real-Time Systems
Let’s define a couple of interesting concepts before closing this article. This classification can help us choose a real-time operating system depending on the needs of our application.
Hard Real-Time Systems
A hard real-time system must meet its deadline 100% of the time. If the system does not meet a deadline, then it is considered to have failed. This doesn’t necessarily mean a failure will hurt someone if it occurs in a hard real-time system only that the system has failed if it misses a single deadline.
Some examples of hard real-time systems can be found in medical devices, such as pacemakers and control systems with extremely tightly controlled parameters. In the case of a pacemaker, if the pacemaker misses a deadline to administer an electrical pulse at the right moment in time, it might kill the patient (this is why pacemakers are defined as safety-critical systems).
What is meant by ‘must meet the deadline’?
It means something catastrophic occurs if the deadline is not met. It is the penalty that sets the requirement.
Soft Real-Time Systems
Soft real-time systems are the most lax when it comes to how often the system must meet its deadlines. These systems often offer only a best-effort promise for keeping deadlines.
Cruise control in a car is a good example of a soft real-time system because there are no hard specifications or expectations of it. Drivers typically don’t expect their speed to converge to within mph/kph of the set speed. They expect that given reasonable circumstances, such as no large hills, the control system will eventually get them close to their desired speed most of the time.
Closing
We close this first article in the FreeRTOS series with a summary: any RTOS for embedded systems consists of several components: the scheduler, objects, and services. The scheduler is a crucial part of the kernel, as scheduling policies define how task execution is carried out. This execution is made possible through context switching, and together, these elements enable multitasking.
Each process or function in our application can be associated with a task managed by the RTOS kernel.
Now that you understand these concepts, you can answer the following question!!….
What is a Real-time system?
Any system that has a deterministic response to a given event can be considered realtime. If a system is considered to fail when it doesn’t meet a timing requirement, it must be real-time. How failure is defined (and the consequences of a failed system) can vary widely.
Deja una respuesta